Adding the two basic functions
Let’s start with the first basic function: Basic Info. Expanding Basic Info, we get Text Stats. In Chapter 4, among others, we imported the neattext package, which is very useful for our statistics as it has a function named word_stats. If you haven’t already imported it, it’s time to do so.
word_stats returns a dictionary, so a key:value data structure; all we need to do is to get the information from it (putting in the word_desc variable), then write everything on the screen in the proper column. The following screenshot shows the code that obviously is part of col1:

Figure 5.13: Text Stats
We can access the stats using a simple key:value combination. However, the logic of the required code is outside the scope of this book, which focuses on Streamlit. The important thing to understand is that any specific function must be coded in the correct column section. This is what we see in our web application:
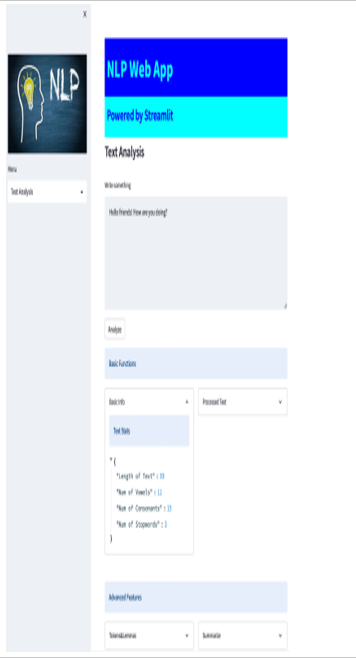
Figure 5.14: Text Stats function effect on the screen
Now, let’s add the second basic function: Processed Text. The nexttext library is also very useful for Processed Text and this task is quite easy. We can jump to the Processed Text part of the code and add a very simple instruction, as illustrated in the following figure:
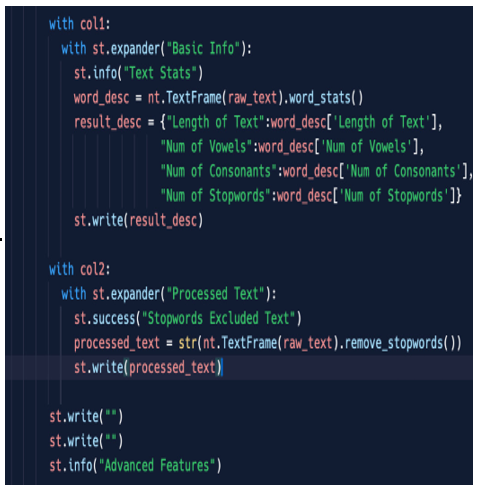
Figure 5.15: The Processed Text expander
We can use neattext’s remove_stopwords() to get the text we input without the stopwords, then cast it to a string (str), and save it in a variable named processed_text; finally, we write the processed text on the screen. This is the result:
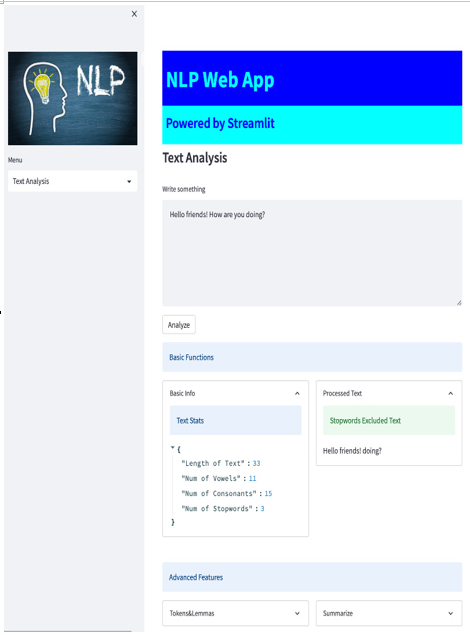
Figure 5.16: The Processed Text function effect on the screen
The result is nice, but we can do even better – for example, writing on the screen the list of the stopwords we removed from the text. Please note that stopwords are, let’s say, common words that don’t add any information to our original text.
We can add this list into the first column, adding to it a second expander exactly below the first one; this is the code:
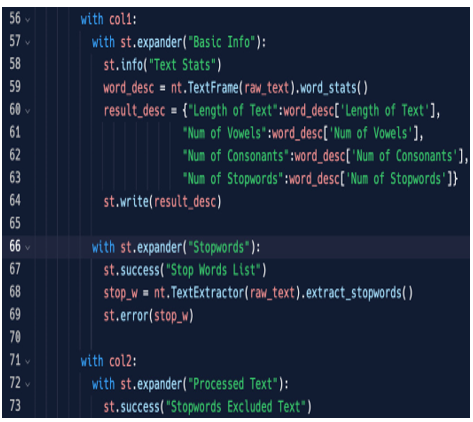
Figure 5.17: The code to extract the stopwords
So, we add a second expander (st.expander()”Stopwords”) and, once again using neattext, we extract stopwords (extract_stopwords) and put them into a variable (stop_w), then print this variable on the screen, this time using st.error. Here is the result:
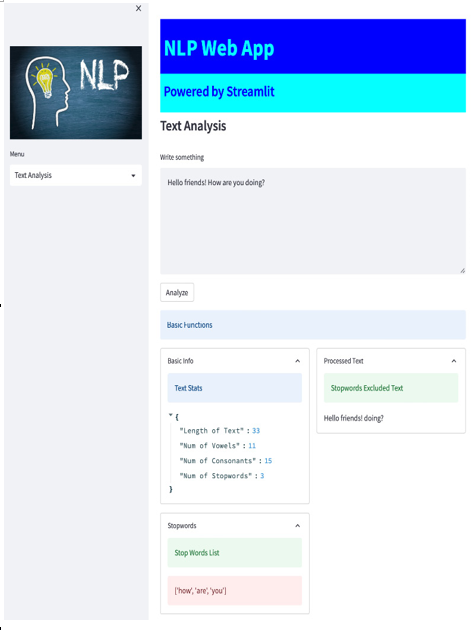
Figure 5.18: Stopwords visualization
Everything is working fine: Text Stats tells us how many stopwords we have, Stop Words List shows us those stopwords in a list, and Processed Text shows the text without these items.